いつもお世話になっている深層学習のComponentを実装した
概要
深層学習で頻繁に用いるDropout層やConvolution層、BatchNorm層、Pooling層などの基本的なComponentをスクラッチで実装したことがなかったため、実装してみた。
コードはこちら。(ライブラリはnumpyのみ使用)
解説
BatchNormalization
BatchNormはミニバッチ毎に正規化を施すもので、各層のActivationの分布が"良い"分布になるようにすることができるものである。この分布が両端に偏ったような形になると勾配消失問題が起き、逆に余りに裾野が狭いとモデルの表現力が乏しいことになる。ある程度広がりを持った健全な分布にしてやりたいという気持ち。
BatchNormの実装はこの記事(Understanding the backward pass through Batch Normalization Layer)を参考にした。逆伝播を計算グラフにより求める方針で、非常にわかりやすかった。
Forwardは図1の通り。ZeroDivision防止の工夫を除けば普通の正規化である。

図1 BatchNormのForward (文献[1])
Forwardは素直に実装すればよいのだが、逆伝播はちゃんと計算しなければならない。
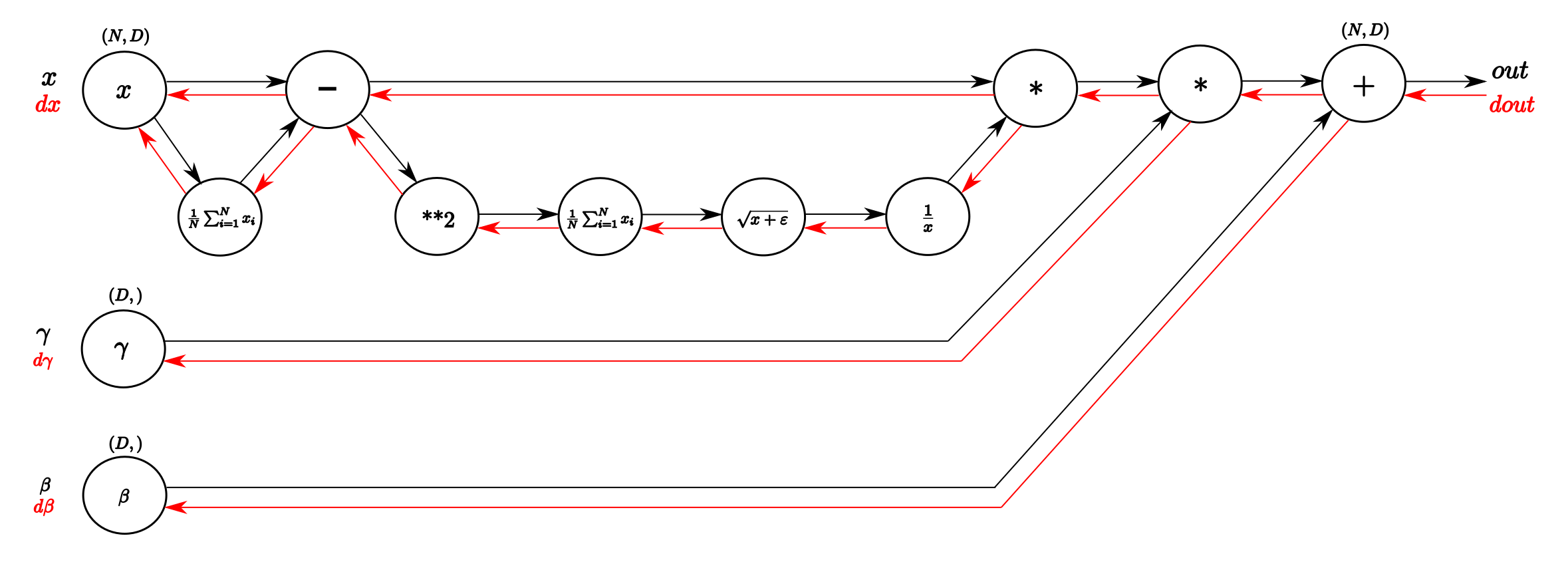
図2 BatchNormのBackward (文献[1])
逆伝播は複雑になってくると図2のようなグラフィカルな手法を使うと分かりやすい。最近読んだPRML[2]では、誤差逆伝播をChainRuleゴリゴリで計算するスタイルであったため、比較して便利だなぁと感じた。この計算グラフを書くことが実装にも直結するため、お得。
BatchNormに限らないが、基本的な実装の流れは、
- Forwardアルゴリズムの定義
- 計算グラフ化
- 計算グラフを用いてBackwardの導出
- それに応じて、Forward時にどの変数をmemorizeしておくべきかチェック
- メンバ変数を決め、コンストラクタを定義
- Forward, Backwardを計算グラフに従って記述
という感じであった。Backwardのために、Forwardで計算した途中経過をメモ化しておく必要があるが、そのメモ化も計算グラフを使えば極めて自然にできる。
計算グラフの各ノードはアルゴリズムの各ステップの演算を表している。つまり、一度各ノードの演算に基づいて部分的な逆伝播を導出すれば、他の様々なものに流用できる。
また、元論文も見てみた(文献[3])。↓
表題は汎化云々よりも学習の高速化を推しているようだ。通常、学習率を大きくしすぎるとパラメータのスケールも増大してしまうため、あまり大きくできない。一方ミニバッチ正規化を施すことでパラメータのスケールに影響を受けなくなる。よって学習率を上げてもイケてしまうという話らしい。
なお具体的には、層のヤコビアン(重みの1階偏微分を並べたもの?)の特異値が1に近づくためであるらしい。これは学習に都合が良い(文献[4])ようだ。層が表現する関数を雑に線形近似すると、層は入力にヤコビアンを乗算する操作をすることになる。このとき、特異値に小さすぎたり大きすぎたりするものがあるとBackPropagationにおいて挙動が不安定になるからである(お気持ち数学でごめんなさい)。
Convolution
Convolution層は、入力データに対して、層が持つパラメータであるフィルタ(カーネル、窓、重み、などなど)を畳み込んで特徴マップを計算する層である。
画像のように空間的な特徴量、localな特徴量が重要な場面で使われる。
また、あまり明示的に意識したことが無かったが、そもそも画像のような多次元配列は全結合層を適用すると(たいていの例では)重みの個数が爆発的に増大する。Convolution層はそれを現実的な個数にしているという面もある。「画像だし畳み込み!w」のような脳死プレイをしていると、新しい技術が出てきたときに何故それが良いのか分からなくなってしまいそうなので気を付ける...(戒め)。
畳み込み演算の詳しい定義などは省略し、実装のまとめのみ。
- [Forward]フィルタ、入力のshapeから出力マップのHeightとWidthを求める(お絵描きor公式利用)
- [Forward]入力を(Batch数 * 出力Height * 出力Width, Channel数 * フィルタHeight * フィルタWidth)の二次元配列に変換する
- [Forward]フィルタを(フィルタ数, channel数 * フィルタHeight * フィルタWidth)の二次元配列に変換する
- [Forward]積和演算
- [Forward](フィルタ数, channel数, 出力Height, 出力Width)の形で出力
- [Backward]は、「集約<->分散」という関係と配列のサイズの変遷を考えて、Forwardと真逆に実装する。
難しかったのは、2, 3で二次元配列に変形する点である。Numpyの行列積の恩恵を受けるために入力とフィルタを二次元配列(行列)にしている。BackwardはShapeを追いながらForwardの逆概念を実装していくイメージで分かりやすかった。
Dropout
Dropoutとは、層のノードの中からランダムに一定割合のノードを選び、それらを使用せずに伝播させる層である。Dropoutをすることで似た構造のネットワークを複数学習させているのとほぼ同一の状況になり、汎化性能が向上する。アンサンブルと気持ちが似ていそう。
Dropoutは非常に簡単だった。ハイパーパラメータとして与えた「削ぎ落す割合」に応じてランダムにindexのmaskを作り、それを乗算すればよい。Backward時にはForward時に用いたindex maskをmemoから呼び出し、それを逆伝播してきた値に乗算すればよい。
なお、ここでの乗算は成分ごとの積である。
元論文はこちら↓(文献[5])。Hinton先生らの論文。
手法を1つ勉強するたびにこういうのを最初に思いついた人はすごいなぁという気持ちになる。
Pooling
Pooling(ここではMax-Poolingを例にとる)は、マップの(例えば)2 * 2エリアごとに最大値を取って、サイズの小さい・より情報の集約されたマップを得る働きをする。学習の高速化、位置の微小な摂動に対するロバスト性といった恩恵が得られる。
基本的にConvolution層と似たような実装をする。目的はシンプルなのだが、Numpyの線形代数演算の恩恵を受けるために、4次元配列を2次元にしなければならない。
まとめ
こういう基礎勉強は好きなので楽しかった。元論文を読んだことは無かったので勉強になった。
しかしなかなか最近の概念を学べていないのでそっちもやらないと...。
参考資料
[1]
[2] C.M.ビショップ著. 『パターン認識と機械学習上』. 丸善出版. 2012年.
[3]
[4]
[5]