『オブジェクト指向のこころ』演習問題 第2章
章の概要
UML(Unified Modeling Language)の話。クラス図と相互作用図を扱った。クラス図はクラス間の静的な関係、相互作用図は動的な関係を表すことができる。
演習問題
基礎
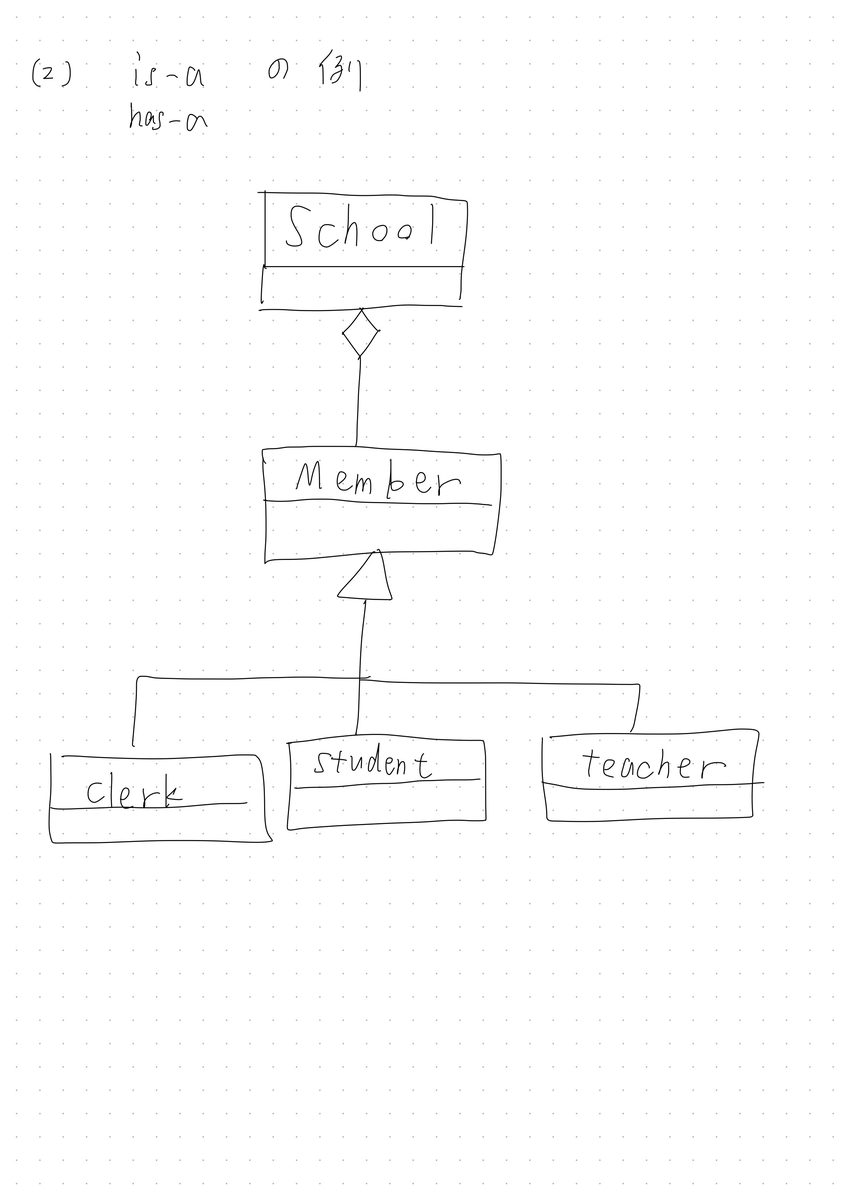
[1] is-a関係、has-a関係の違い
is-a: あるクラスが他のクラスの一種である関係
has-a: あるクラスが他のクラスを保持している関係
has-a: には(1)Compositionと(2)Aggregationの2つがある。
[2]クラス図の3つの要素
- クラス名
- データメンバ (accessibility含む)
- メソッド(accessibility含む)
[3] カーディナリティとは
クラスに対して、存在できるインスタンスの個数
[4] シーケンス図の目的とは
オブジェクト間のメッセージのやりとりを、処理の順番にしたがって表現すること
応用
[1] is-a関係の例、has-a関係の例
[3] "処理を起動する"というより"メッセージを送信する"といった方が良い理由とは
OOPはオブジェクトがその他のオブジェクトに対して処理を委託する(責任を移譲する)枠組みであるため。処理を起動するというと、手続き型っぽい表現になる。
『オブジェクト指向のこころ』演習問題を解いていく
概要
『-デザインパターンとともに学ぶ-オブジェクト指向のこころ』という本を読んでいくことにした。オブジェクト指向については基本は分かっているつもりだが、先月、
「デザインパターン知ってる?」
「何もわからん...」
という事態に遭遇して、TODOリストにぶっこんでいたデザインパターンをやらねばと思ったのが経緯である。
全25章で、各章に演習問題(実装というよりも考えの確認のようなもの)が付いていたため、自分なりの解答を書いていくことにした。テストじゃないので解答はラフに書いている。厳密性よりもイメージ重視。
目次 (各章へのリンク)
[1]
『オブジェクト指向のこころ』演習問題 第1章 - Riguo’s blog
[2]
『オブジェクト指向のこころ』演習問題 第2章 - Riguo’s blog
[3]
『オブジェクト指向のこころ』演習問題 第1章
章の概要
機能分解的なアプローチでは、一部分に責任が集中しすぎて変更に弱い設計になってしまう。OOPを考える上で、概念レベル・仕様レベル・実装レベルの3つの抽象度があり、各オブジェクトの持つ責任を明らかにするとうまく設計できる。OOP3原則と言われる継承・ポリモーフィズム・カプセル化はこの責任を明示する設計の過程で自然に欲しくなる。実装レベルの概念(クラスとかpublic継承とかメソッドのオーバーライドとか)によりこれらが実現される。
演習問題
基礎
[1] 機能分解の基本的なアプローチを解説せよ。
所望の機能を実現するための流れを細かい機能に分割し、それらを全て制御するメインプログラムに責任を投げる。
[2] 要求の変更を引き起こす主な理由3つとは。
・ユーザーのドメイン知識が増えてニーズが変わる
・開発者のドメイン知識が増えて考え方が変わる
・ソフトウェア開発を取り巻く環境が変化する
[3] 機能に着目するより責任に着目するほうが良い。例えば?
分解して得られた機能の全てを考えようとすると辛い。各オブジェクトが何を実現すれば良いのかを概念レベルで考えるようにすれば、自然とまとまりができる。これにより高い凝集度と低い結合性が実現できる。よって、保守性・可読性・効率が良くなる。
[4] 結合度・凝集度とは
結合度:2つのルーチン間の関連の強さ。低いほうが良い。
凝集度:各ルーチン内の演算の関連性の強さ。高いほうが良い。
[5] オブジェクトにとってのインタフェースの目的とは
オブジェクトのユーザに対し、必要以上の情報にアクセスしなくて済むように制限すること。外部から見てオブジェクト内部の具体的な動きが見えないように抽象化すること。
[6] クラスのインスタンスの定義は?
あるクラスを型としてみたときに、その型をもつ実体化されたオブジェクトのこと。
[7] オブジェクトが定義する3つの観点とは?
・オブジェクトが保持するデータ項目の情報
・オブジェクトが実行できるメソッドの情報
・これらへのアクセス方法
[8] 抽象クラスとは
いくつかの具体的なクラスの共通部分をくくりだし、継承の元にする。抽象度・
再利用性が上がる。具象クラスをカプセル化できる。
[9] オブジェクトが保持できるアクセス可能性の種類
・public (外部からアクセス可能)
・protected (一段階継承した先まで外部からアクセス可能)
・private (外部からアクセス不可能)
[10] カプセル化とは?
様々な隠蔽のこと。オブジェクトがデータへのアクセス可能性を定めることでメンバを隠蔽したり、抽象クラスが具象クラスを隠蔽し、細かな具体的な派生を気にしなくてよくなったり。
例) public メンバー
例) Student (抽象クラス) -> 学部生・大学院生・ポスドク、などの具象クラス
一律にstudentとして扱える。
[11] ポリモーフィズムとは?
関連するオブジェクトたちに対して、そのオブジェクトの型毎に特化したメソッドを実装できる能力のこと。同名のメソッド、アクセスのための記述が同じ文法、というようにすれば、ユーザーはある一つのアクセス方法をしつつも、各オブジェクトはそれぞれに特化した処理が可能になる。
[12] OOPを考える3つの観点
・概念レベル
・仕様レベル
・実装レベル
応用
[1] ソースコードを分割するための「モジュール」の有効性
変更に取り組む際に対応する部分だけを変更すればよい。
[3] カプセル化の利点
・ユーザーは見れる機能が限られることで考えるのが楽になる
・開発者側は呼び出し側のことを気にせずに変更できる。
・他のオブジェクトから内部処理を隠すことで抽象化する。
・オブジェクトにデータと責任を込めて実装することで、外部が変更されたときにそのオブジェクトには何ら影響が無いため、バグを減らせる。
Self-Critical Sequence Trainingを用いたChatbotを作った
内容
コード
スライド
概要
強化学習の他領域への応用に興味があり、NLPとの融合を試してみた。
ChatbotはPyTorchのチュートリアル(Chatbot Tutorial — PyTorch Tutorials 1.8.0 documentation)でも紹介されている、Cornell Movie-Dialogs Corpus & seq2seqモデルという簡単な設定で作成した。Botのインタフェースはpython-telegram-botを使用した。なお、このプロジェクトはスプリングセミナー2021:深層強化学習 | Deep Learning JP の最終課題として作成したものである。
seq2seqモデルを通常通りcross-entropy lossで学習した後、以下のように強化学習の問題としてとらえ直し、REINFORCEを発展させたSelf-Critical Sequence Training(SCST)という手法でfine-tuneした。
Agent: seq2seqモデルにおけるdecoder
Environment: ユーザーによって投げかけられるフレーズ
Action: 対応するフレーズ(reply)の生成
Reward: BLEUスコア (2つの系列の類似度を測る指標)
結果
詳しくはスライド参照。
test scoreは向上したが、汎化性能の向上は調べ切っていない。
Botの返答としては、fine-tuneにより疑問文への正しい形式への応答ができるようになり、コーパスのセリフをそのまま発しているような現象は見られなくなった(不自然な人物名・固有名詞が出てくるなど)。
参考文献
[1] Papineni, K., Roukos, S., Ward, T., & Zhu, W. (2002). Bleu: a Method for Automatic Evaluation of Machine Translation. ACL.
[2] S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross and V. Goel, "Self-Critical Sequence Training for Image Captioning," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 1179-1195, doi: 10.1109/CVPR.2017.131.
強化学習のセミナーに参加してみた
概要
東大の松尾研究室が主催しているスプリングセミナー2021深層強化学習に参加してみました。正確には2021/3/13現在参加中です。
松尾研のセミナーは初めて参加しました。参加する前は各分野のイントロを速習し、分野に対する馴染みを持とうというレベルだと思っていました。しかし実際には、2019-20年の論文の成果など、最新の潮流も踏まえた授業になっていて、(深層)強化学習に入門しつつも、最新の流れがどのようなものかを把握できるものになっていました。参加して非常に満足しています。
内容
セミナーは全6回の授業と、最終プロジェクトから構成されています。
各授業は講義パート+演習パートから構成されています。
演習パートでの実装は全ての講義が終わり次第整理する予定。
第1回
- 強化学習: Agentが環境で得る報酬の総和(収益)を最大化する方策を学習する. その目的関数として、価値関数がある。
- 状態価値関数 V_π(s) = E_π[R_{t+1} | S_t = s] : ある状態sから方策πに従って行動した場合に得る収益の期待値
- 行動価値関数(Q関数) Q = E[R_{t+1} | S_t = s, A_t = a] : ある状態sで行動aを行い、その後方策πに従った場合に得る収益の期待値
- 方策 π(s|a): ある状態sで行動aを選択する確率
- ベルマン方程式: 価値関数の定義から導かれる再帰的な式。ある方策πの下での状態・行動ペアに対して価値関数を求められる。->方策を評価できる
- モデルベース強化学習: 環境モデル(遷移関数・報酬関数)が明らかな場合、それをベースに方策を学習する
- モデルフリー強化学習: 環境モデルを持たず、環境からサンプリングして方策を学習
- On-Policy: 学習対象の方策と同じ方策で得た経験を用いて方策を改善する。学習は安定するが、更新前の方策でのサンプルを捨てることになり、サンプリング効率は悪い。
- Off-Policy: 挙動方策で得た経験を、学習対象の方策の改善に使う。過去の方策でサンプルした経験を使えるのでサンプリング効率が良い。その代わり学習は安定しづらい。
- 各手法(TD学習、Q学習、SARSA)
- 状態空間が連続な場合、極めて大きい場合、関数近似を行う(方策・価値関数共に)-> 関数近似器としてのDNN
- 方策を関数近似する手法として、方策勾配法。方策をパラメトライズし、その方策からなる目的関数を勾配法で最適化する。
- 方策勾配定理: 方策勾配を別の形で書き表した定理。ここからREINFORCEとActor-Criticの2手法を得る。
- REINFORCE: 方策勾配中のQ関数を収益Rでそのまま置き換える。Rの分散を抑えるためにベースラインb(定数)を引いたR - bで置き換える。
- Actor-Critic: 方策勾配中のQ関数を、パラメトライズした価値関数の近似器で置き換える。方策を表現するモデル(Actor)と価値関数を表現するモデル(Critic)の両方を同時に学習するため、Actor-Criticという。
- Actor-Criticの手法(DPG, DDPG, A3C, SAC(強い)など)
- DQN: DNNをQ関数の近似器として用いる。過去の経験をReplay Bufferに保存しておき、学習の時にバッファからランダムに経験を選んでミニバッチ学習を行う。これをExperience Replayという。
- Prioritized Experience Replay: バッファ中の経験に対して、TD誤差が大きいものに対して高い優先度を割り当てる。
最終プロジェクト
まだ
期間がかなり限られているので大きなものはできませんが、ペンシルベニア州立大学らによるリソースを活用して、強化学習の交通信号制御への応用をやろうと思っています。ラズパイとかArduinoとかでロボット学習や自動運転の実機デモなんかができればよかったですが、期限的に厳しそう...
traffic-signal-control.github.io
【読書記録】『プログラミングの基礎』
【読書記録】Deep Learning With PyTorch
本の概要
PyTorchの基礎~医用画像解析プロジェクトまでをカバーしている。
以前無料でPDFが配布されていて、そこで入手していた。(もちろん公式のモノ)
コード・実行環境
(著者のコードを写経したり少しいじったり、モジュール化して使えるようにしただけなので掲載しない)
実行環境は簡易的に書くと
Ubuntu18.04 (on WSL2)
Geforce RTX2070(8GB)
Docker 20.10.3
CUDA11.0
Python3.8.0
Pytorch1.7.1等
GPUはもともとゲーミング用途で購入した。そのためWindows環境しかなく、デュアルブートするのも怖いのでWSL2を使ってUbuntuでの開発環境を整えている。WSL2の進化は本当にすごくて、CUDAに対応したため、ローカルの計算資源もUbuntuから使うことができる。Dockerも使えるのでホスト環境を汚さずに済む。ただしWSL2の仕様上やたらにメモリを食うので、しばしば学習が落ちてしまい、本の内容を全ては実行できなかった。設定すればメモリ使用量制限できたりするらしいのでやらねば。。一部計算をColabで補ったりした。
[余談]
正直Windowsの有難みはゲームとOfficeくらいなので、Steam(ゲームのプラットフォーム)がLinuxに対応してくれたらもうWindow要らないんだよなぁ...。WSL凄いけど当然しばしば問題も起こるので、Linux単機を構築したいところ...。
読んだ目的
KaggleなどでPyTorchは使ったことがあるが、しっかり分かっているとはお世辞にも言えなかった。また、込み入ったプロジェクトにおける綺麗な実装例を学びたかった。そしてなにより無料であったため。
読んだ後の実感
PyTorchのTensorがメモリ上でどう管理されているかといった部分など、普段表面的に使っているだけでは意識しないようなことも学べた。総じてPyTorch力が上がった気がする。
また、CT画像を用いて肺がん検出を行うHandsOnがあり、これも非常に勉強になった。CT画像の扱い方や座標変換方法といった要素も学べたが、それ以上にプロジェクト全体をどう切り分けてコードを書いていけばよいのかが示されていた。
今回であれば、
- DataLoad
- Segmentationによる結節位置検出
- 結節のGrouping
- 分類モデルによる結節候補の分類
- 悪性/良性の診断
という段階に分けることができ、それぞれにおいて再利用性の高いコードを書く経験ができた。実装が非常に綺麗で、とても参考になった。ログをいつ出力するべきか、全体のボトルネックになる場所はどこか、高価な計算資源を最大限活用できているか、などのPracticeも学んだ。
評価指標の考え方なども参考になった。医療現場では陽性を見落とす(False-Negative)と大変なことになるため、偽陰性を減らすように方針を決め、TensorBoardなどで学習を可視化しながら、色々いじっていく、という流れが体験できた。TensorBoardはチュートリアルレベルしかやったことがなかったので、便利だなぁと思った。使いこなすのは大変そう。
最終章ではおまけ程度だがモデルのデプロイなども学べた。Flaskを用いてWebサーバーにデプロイしたり、C++でPyTorchを使って高速化したり、JIT化による恩恵を得たり、などである。最後のAndroidへのデプロイは、Javaの知識が無いため飛ばしてしまった。エッジ向けのモデルの軽量化や、DNN向けハードウェアに渡す際にONNXというフォーマットが用いられることが多いことを学んだ。ここら辺のエッジコンピューティングやハードウェアと協調してアルゴリズムを考えていくあたりがとても興味があるため、今後もこのあたりを学びたいと思った。
本の内容メモ(自分用)
第1部
Pytorchの環境構築
Pytorchの基礎
Pre-trainedモデルの使い方
Tensorの内部実装
- Tensorは初期化時にStorageに要素が格納され、メモリアドレスのOffsetと次元ごとのindexの幅(Stride)の情報を持つ。これによりコピーし直すことなくShapeに応じたアクセスが可能になる。これをviewといって、転置などの演算もStorageをいじることなく可能になる。
- Inplaceな操作はメソッド名に_が付く
Tensorで色々なデータを表現してみる
線形回帰を敢えて勾配法でやってみる
線形回帰で十分なデータに対して、敢えてニューラルネットワークを適用してみる
画像データに対して基本的なCNNを構築
3次元画像データの扱い方
第2部
CT画像から肺がんを早期検知するプロジェクトの構成
- DataLoad
- Segmentationによる結節位置検出
- 結節のGrouping
- 分類モデルによる結節候補の分類
- 悪性/良性の診断
に分けて実装
CT画像は患者座標系からindex-row-column座標系へ変換して扱う
AnnotationDataも盛り込む
分類モデルは簡単なCNN
SegmentationはU-net(
[1505.04597] U-Net: Convolutional Networks for Biomedical Image Segmentation
)を使用。
分類は3次元画像のまま扱い、Segmentationは3次元画像として構成せずに2次元画像を多Channelにしたものとして扱う。空間的な情報は抜け落ちるので、モデルにそこも学習させてあげる必要があるが、3次元でSegmentationを行うよりはコストが小さい。
[性能向上手段]
有効なData AugmentationとしてElastic Deformation(画像にDistortionを掛けるやつ?)や、Mixup(入力として、複数の画像が混合されたものを入れて予測を安定させる)
マルチタスク学習(評価する出力以外の出力も追加で学習することで、目的のタスクに対する性能が向上する可能性がある)
第3部
Pytorch JIT (要チェック)
Pythonの並列化にはGIL(Global Interpreter Lock)がネックになる。Python環境でモデルを実行しなれければこの影響を受けることはない。
PytorchはC++で書かれた内部ライブラリに演算を投げている。
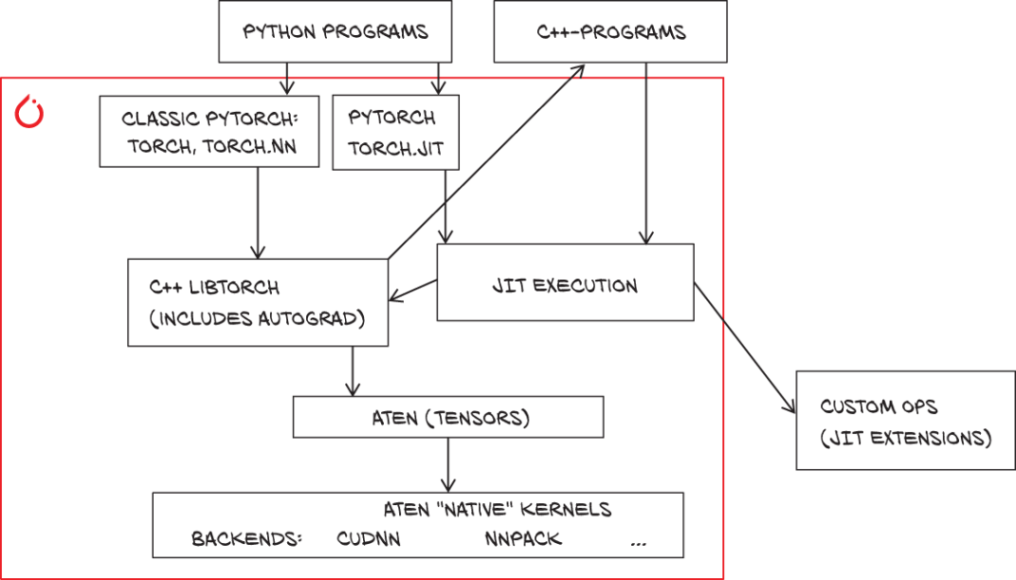
Python, C++の両方からJIT関数にアクセスでき、そこかC++ LibTorchが呼ばれ、ATen(Tensor計算ライブラリ)とバックエンド達が呼ばれる。
Pytorch C++でJIT化したモデルを呼び出せば、Pythonを介さずにできる。もちろんC++で書くのもok.
C++のPytorchはちゃんと勉強したい
モバイルへのデプロイ(TODO)
モデルの軽量化
- 枝狩り
- 量子化(特に int8がよく使われる)
量子化は、ビット数減少による丸め誤差をランダムなものと考え、畳み込みと線形層を重み付き平均のようにとらえれば、丸め誤差は相殺される。中心極限定理。
floatからintへ変換することで、固定精度になる。これは重みの微小な変化を無視することが期待できる。ある種正則化のような感じ。